SeaBorn
Seaborn
O Seaborn é uma biblioteca de visualização de dados para Python baseada no Matplotlib e integrada ao Pandas. Ele facilita a criação de gráficos estatísticos bonitos e informativos com poucas linhas de código.
URL: https://seaborn.pydata.org/
Instalando os pacotes necessários
!pip install seaborn==0.12.2
Importando as bibliotecas que serão utilizadas
import random
import numpy as np
import pandas as pd
import matplotlib as mat
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
import seaborn as sea
%matplotlib inline
Criando os gráficos com Seaborn
Carregando um dos datasets que vem com o seaborn para estudo
dados = sea.load_dataset("tips")
dados.head()
out:
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
Criando gráficos bivariados e univariados na mesma área de plotagem
# O método joinplot cria plot de 2 variáveis com gráficos bivariados e univariados
sea.jointplot(data = dados, x = 'total_bill', y = 'tip', kind = 'reg')
out:
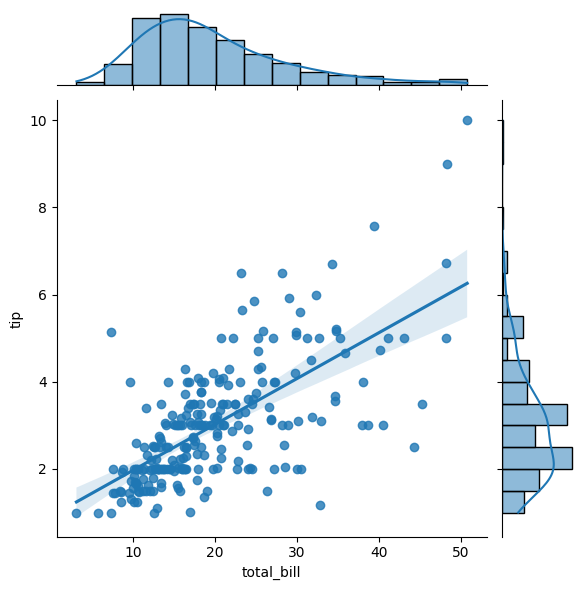
Ele retorna um gráfico que diz: Os pontos são a relação entre valor da conta e gorjeta, a linha azul diagonal é o modelo de regressão, a área sombreada entre ela é o intervalo sendo a margem de erro, temos o histograma da variável total_bill e o gráfico de densidade! Tanta coisa em apenas 1 gráfico!
Criando um gráfico que contém modelos de regressão
# O método lmplot() cria a plot com dados e modelos de regressão
sea.lmplot(data = dados, x = 'total_bill', y = 'tip', col = 'smoker')
out:
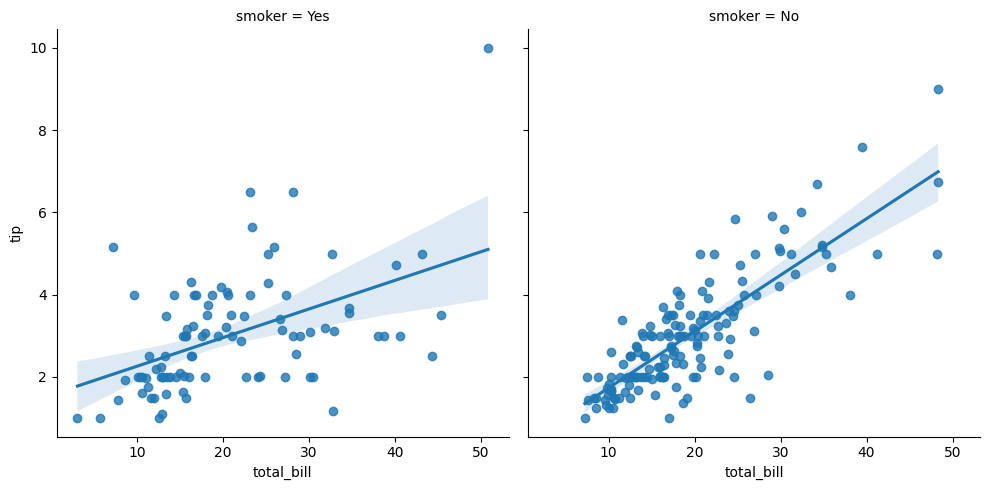
Temos a linha de regressão entre total_bill e tip, isso quando, o cliente era fumante ou não (Smoker True ou False)
Vamos criar um DF vazio
# Criando um dataframe vazio
df = pd.DataFrame()
Vamos preencher o DF com valores vazios
# Alimentando o dataframe com valores aleatórios
df['idade'] = random.sample(range(20, 100), 30)
df['peso'] = random.sample(range(55, 150), 30)
Verificando a forma do DF
df.shape
out: (30, 2)
Visualizando os dados com pandas:
df.head()
out:
| idade | peso | |
|---|---|---|
| 0 | 24 | 58 |
| 1 | 81 | 68 |
| 2 | 86 | 133 |
| 3 | 48 | 69 |
| 4 | 58 | 97 |
Gráfico de dispersão
Criando um gráfico de dispersão com um modelo de regressão na mesma área de plotagem
# O fit_reg nos retorna um modelo de regressão
sea.lmplot(data = df, x = 'idade', y = 'peso', fit_reg = True)
out:
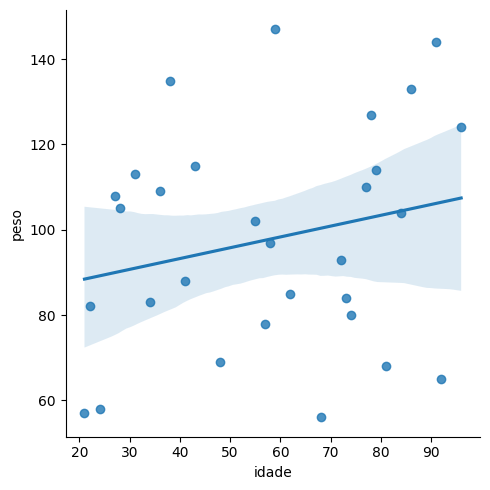
Gráfico de densidade
Criando um gráfico de densidade
# Gráfico de densidade
sea.kdeplot(df.idade)
out:
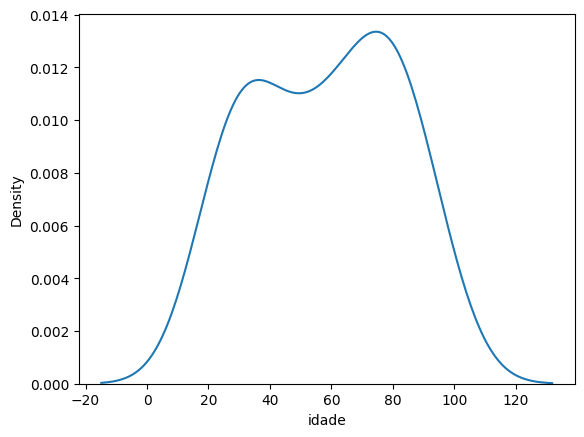
Gráfico de densidade com histograma
Criando um gráfico de densidade com um histograma na mesma área de plotagem
sea.distplot(df.peso)
out:
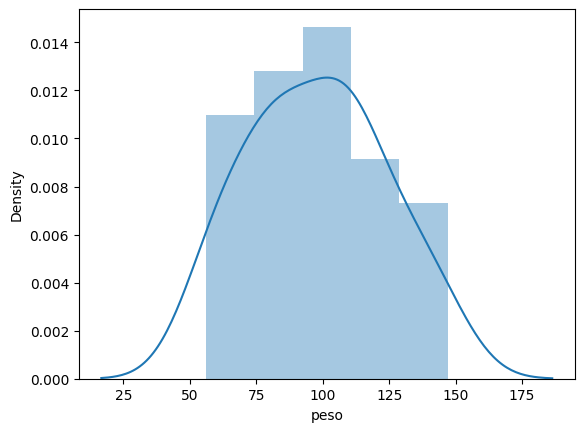
Histograma
Criando um histograma com um rugplot incluso
# Utilizando o histograma do matplotlib, com o rugplot do seaborn
plt.hist(df.idade, alpha = .3)
sea.rugplot(df.idade)
out:
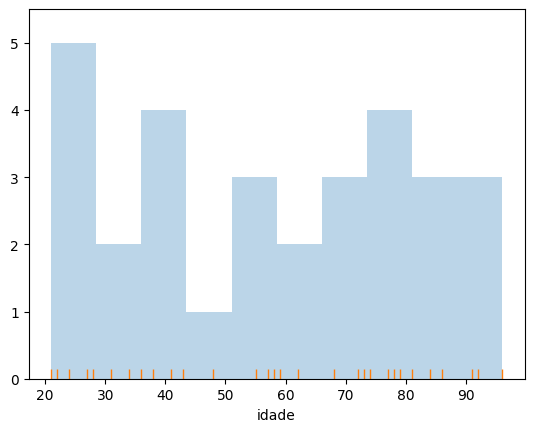
BoxPlot
Criando um gráfico boxplot
sea.boxplot(df.idade, color = 'm')
out:
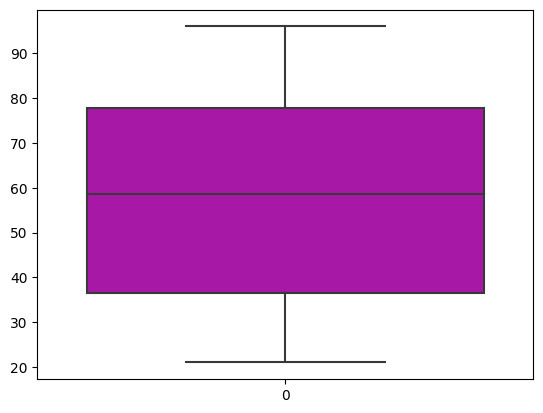
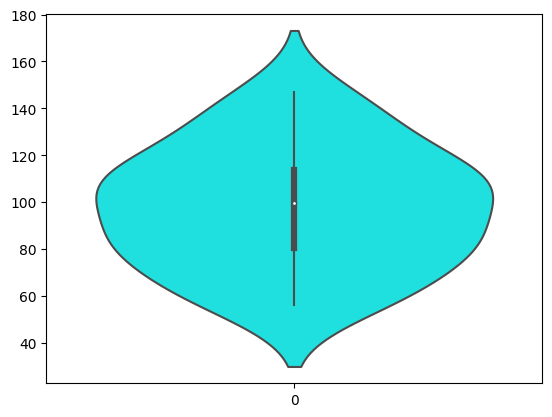
Violin Plot
Criando um gráfico Violin
sea.violinplot(df.peso, color = 'cyan')
out:
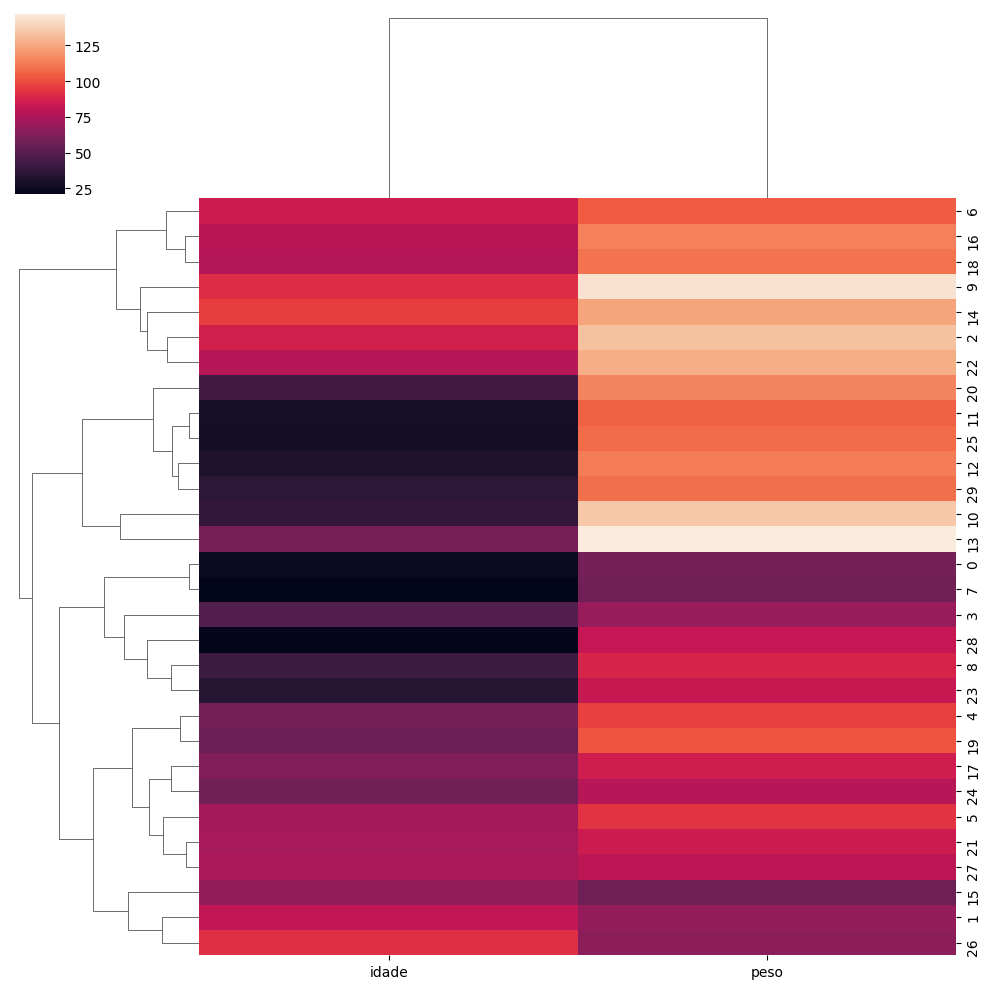
Cluster Map
Criando um Gráfico Cluster Map
sea.clustermap(df)
out: